CrossMAE
Rethinking Patch Dependence for Masked Autoencoders
TL;DR: Learning visual representation doesn't require the model to generate self-consistent images.
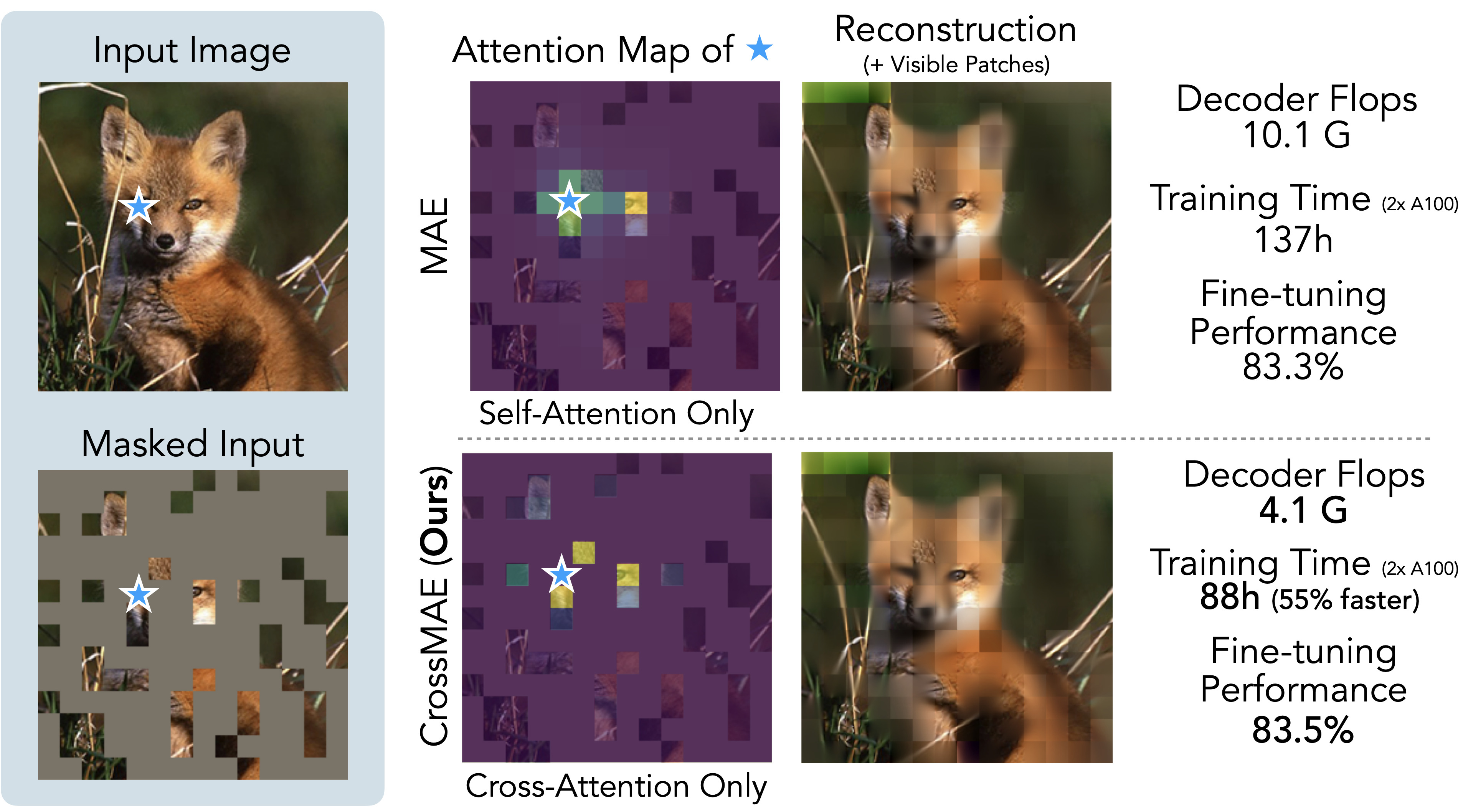
Overview
We introduce Cross-Attention Masked Autoencoders (CrossMAE), which use only cross-attention for decoding in MAE. We show that CrossMAE greatly enhances efficiency and performance in tasks like ImageNet classification and COCO instance segmentation, with significantly reduced computational demands.
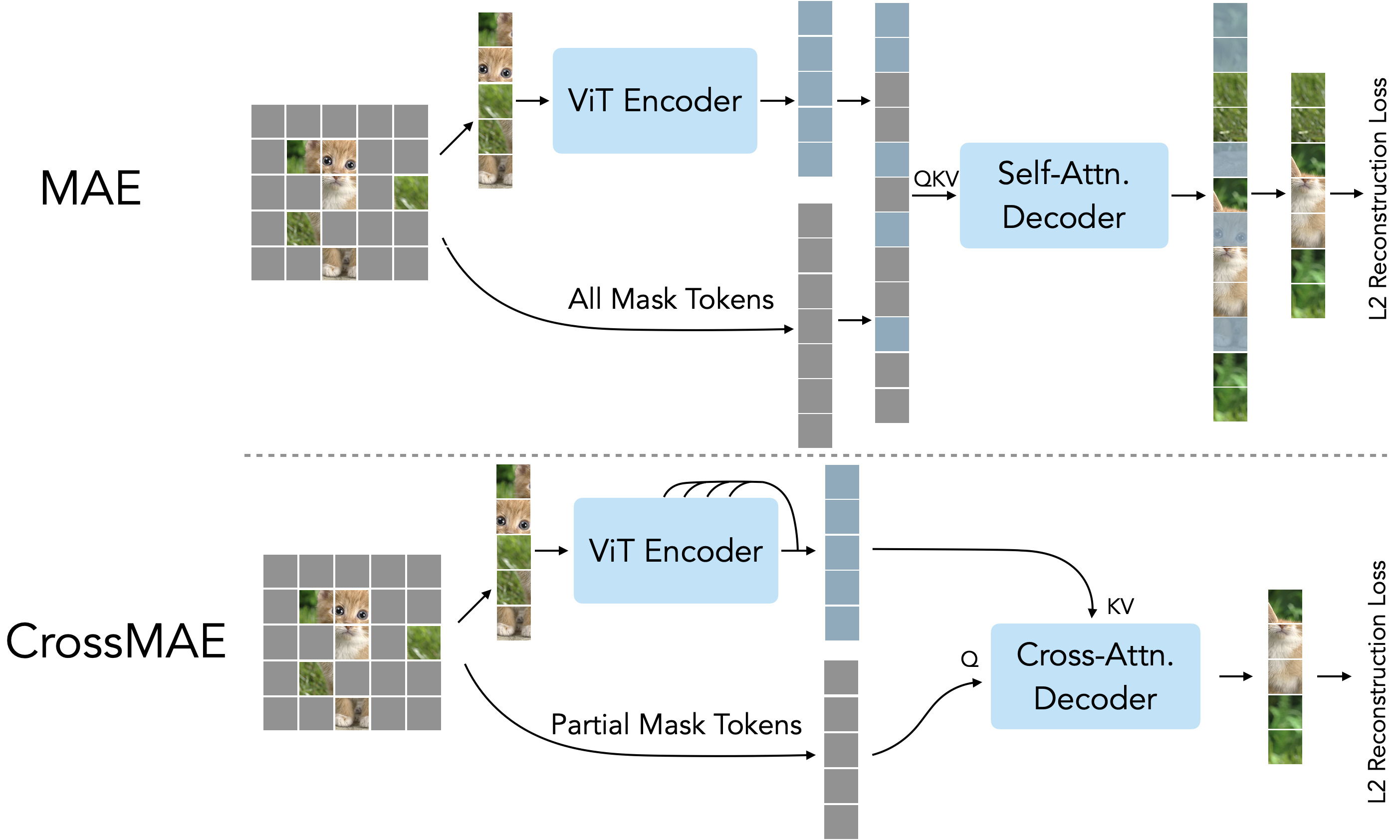
MAE concatenates all mask tokens with the visible patch features from a ViT encoder and passes them to a decoder with self-attention blocks to reconstruct the original image. Patches that correspond to visible tokens are then dropped, and an L2 loss is applied to the rest of the reconstruction as the pretraining objective. CrossMAE instead uses cross-attention blocks in the decoder to reconstruct only a subset of the masked tokens.
Cross-Attention, Partial Masking, and Inter-block Attention
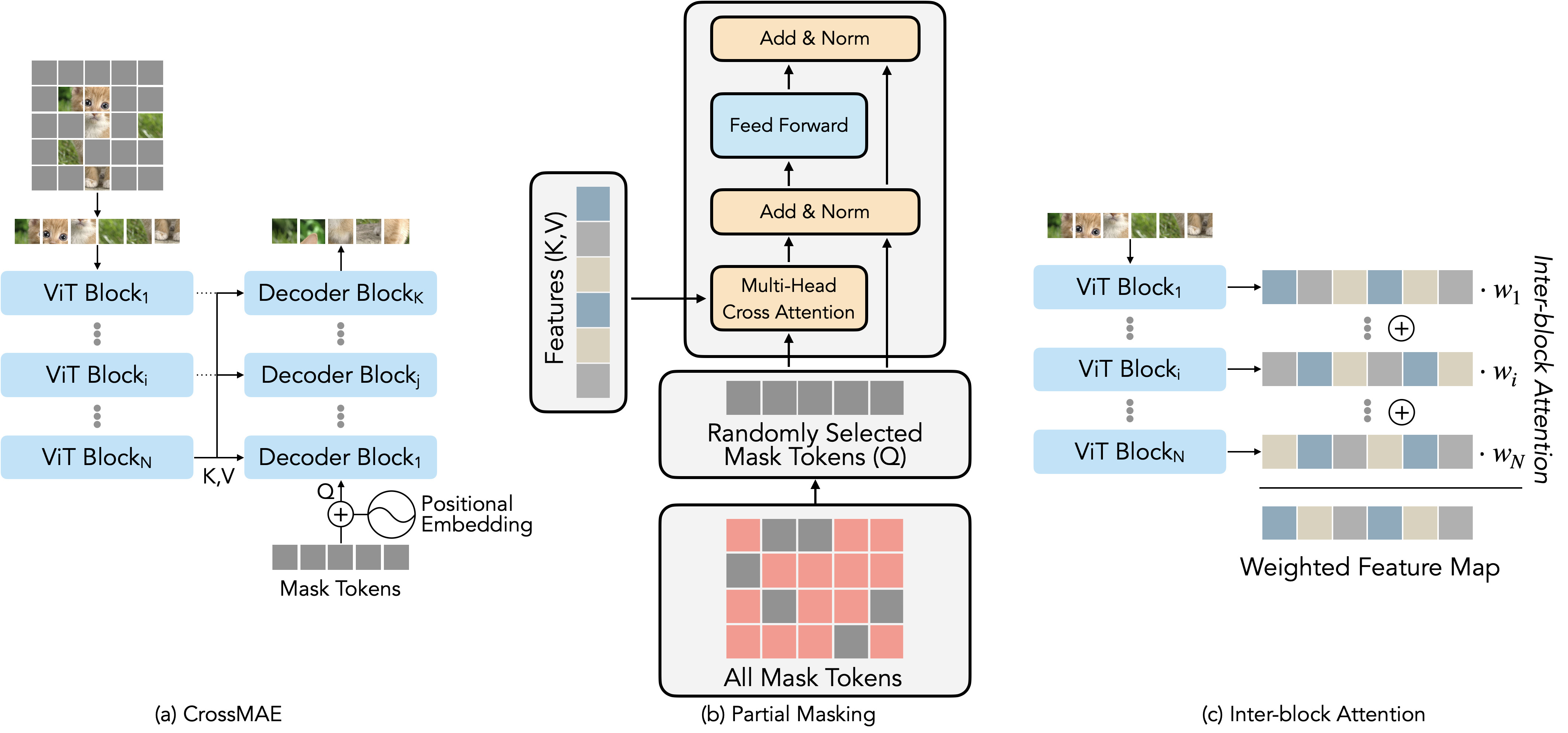
Overview of CrossMAE. (a) The vanilla version of CrossMAE uses the output of the last encoder block as the keys and queries for cross-attention. The first decoder block takes the sum of mask tokens and their corresponding positional embeddings as queries, and subsequent layers use the output of the previous decoder block as queries to reconstruct the masked patches. (b) Unlike the decoder block in Transformers, the cross-attention decoder block does not contain self-attention, decoupling the generation of different masked patches. (c) CrossMAE's decoder blocks can leverage low-level features for reconstruction via inter-block attention. It weighs the intermediate feature maps, and the weighted sum of feature maps is used as the key and value for each decoder block.
Visualizations

Example reconstructions of ImageNet validation images. For each set of 5 images, from left to right, are the original image, masked image with a mask ratio of 75%, MAE, CrossMAE (trained to reconstruct 25% of image tokens, or 1/3 of the mask tokens), and CrossMAE (trained to reconstruct all masked tokens). Since CrossMAE does not reconstruct them, all model outputs have the visible patches overlaid. Intriguingly, CrossMAE, when trained for partial reconstruction, can decode all mask tokens in one forward pass (shown above), which deviates from its training methodology. Its comparable reconstruction quality to full-image-trained models suggests that full-image reconstruction might not be essential for effective representation learning.
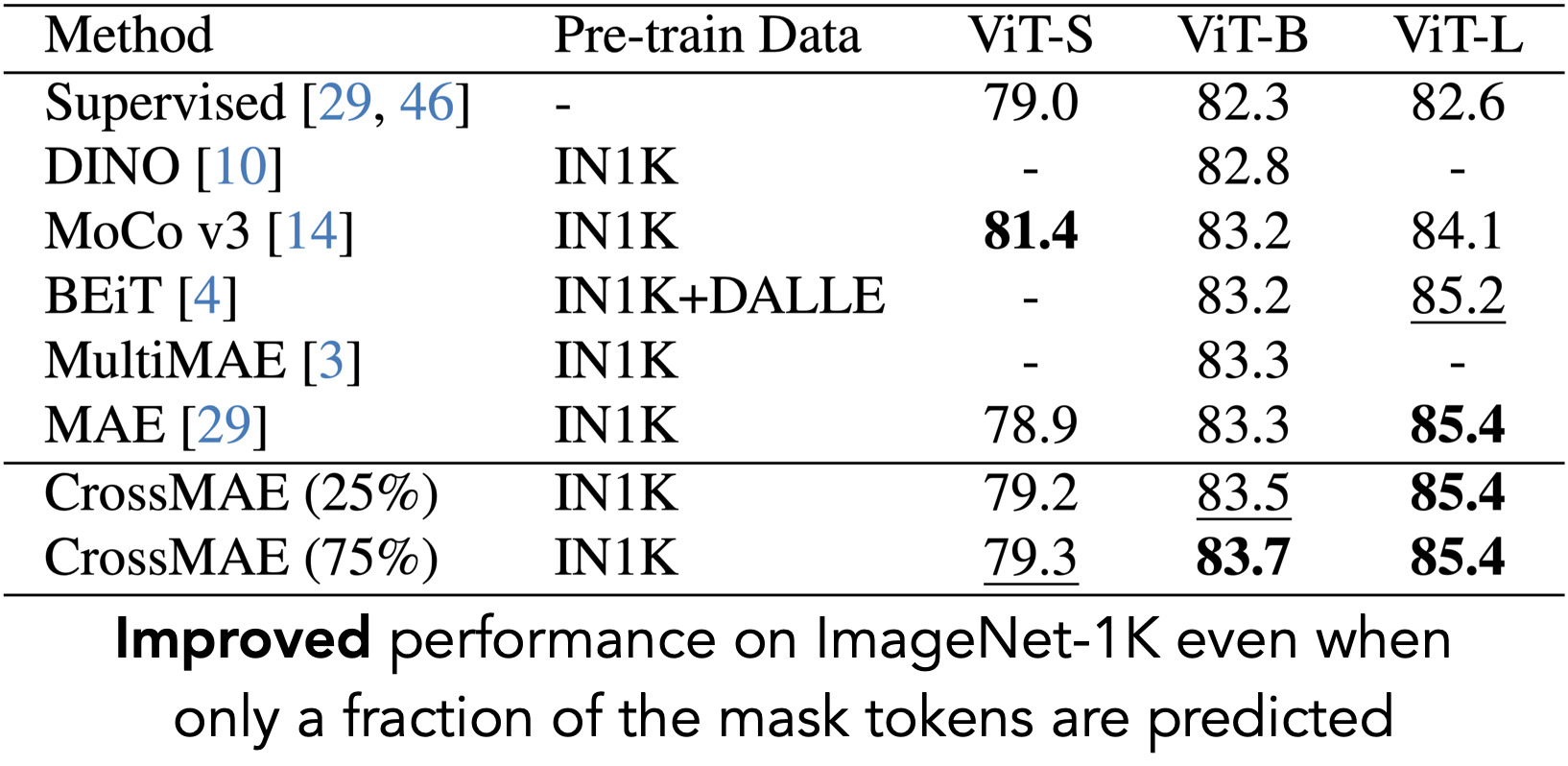
Results
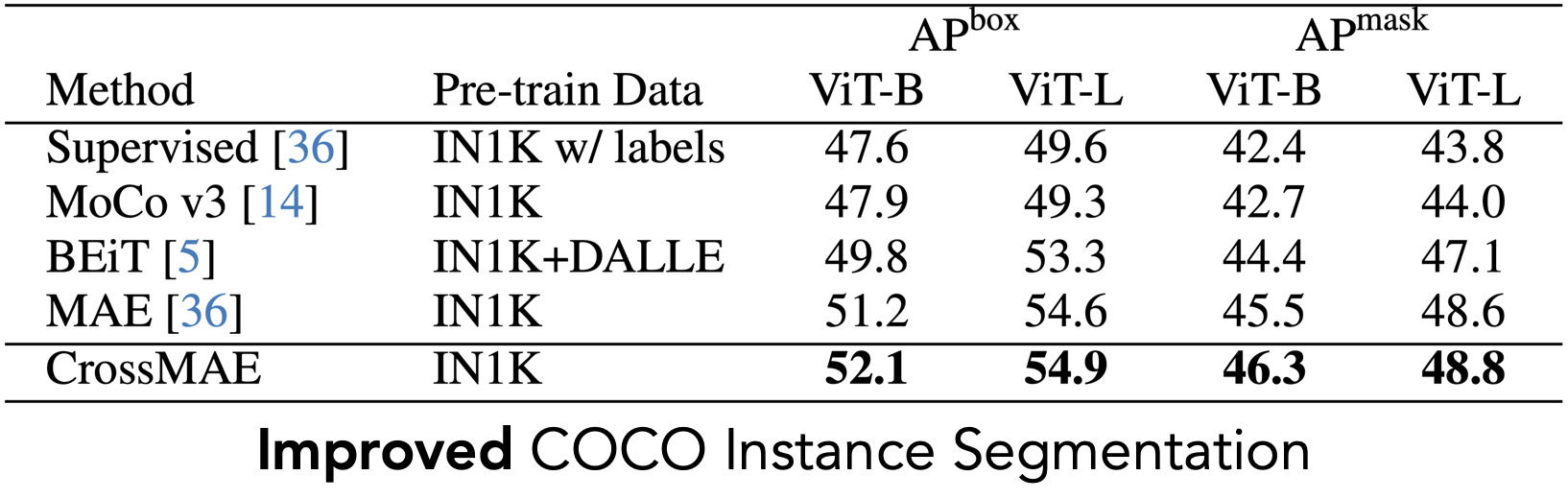
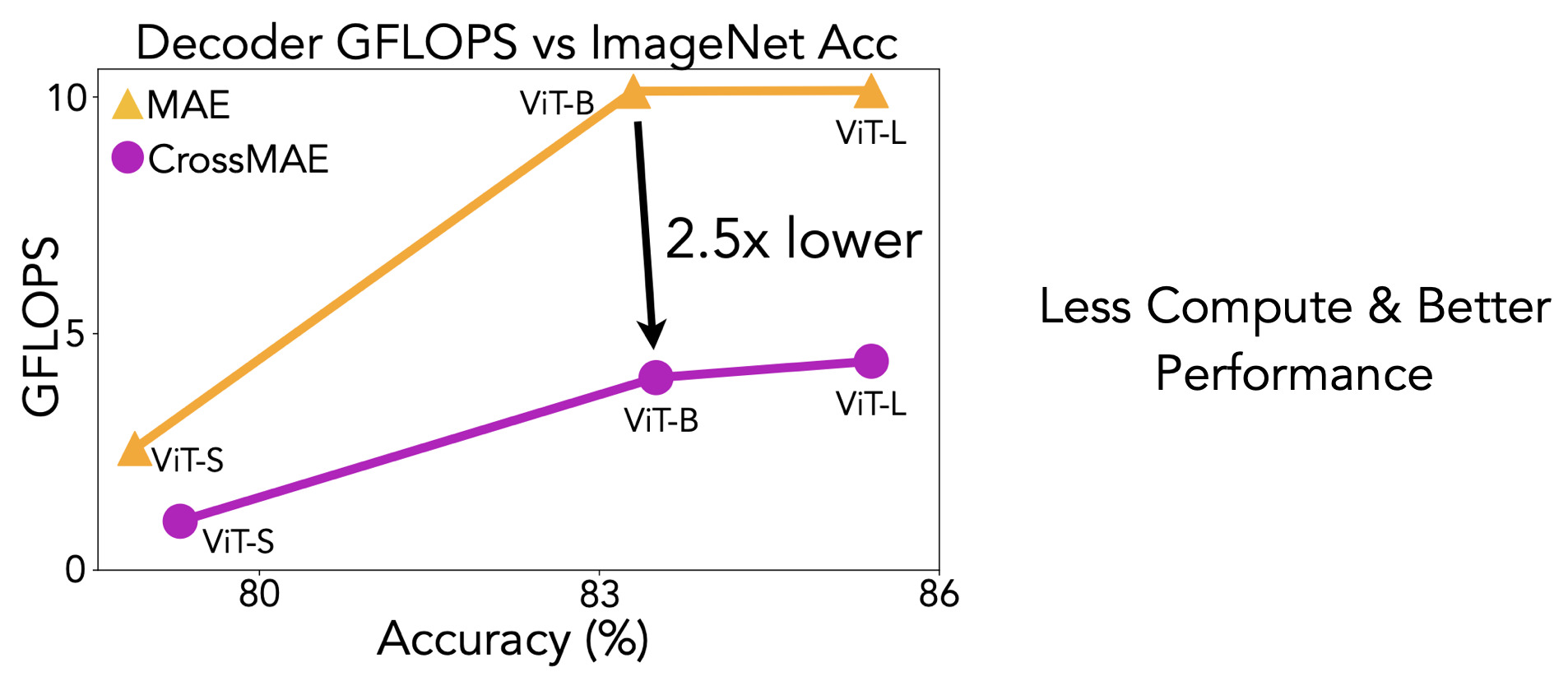
Citation
If you use this work or find it helpful, please consider citing our work.
@article{fu2024rethinking,
title={Rethinking Patch Dependence for Masked Autoencoders},
author={Letian Fu and Long Lian and Renhao Wang and Baifeng Shi and Xudong Wang and Adam Yala and Trevor Darrell and Alexei A. Efros and Ken Goldberg},
journal={arXiv preprint arXiv:2401.14391},
year={2024}
}